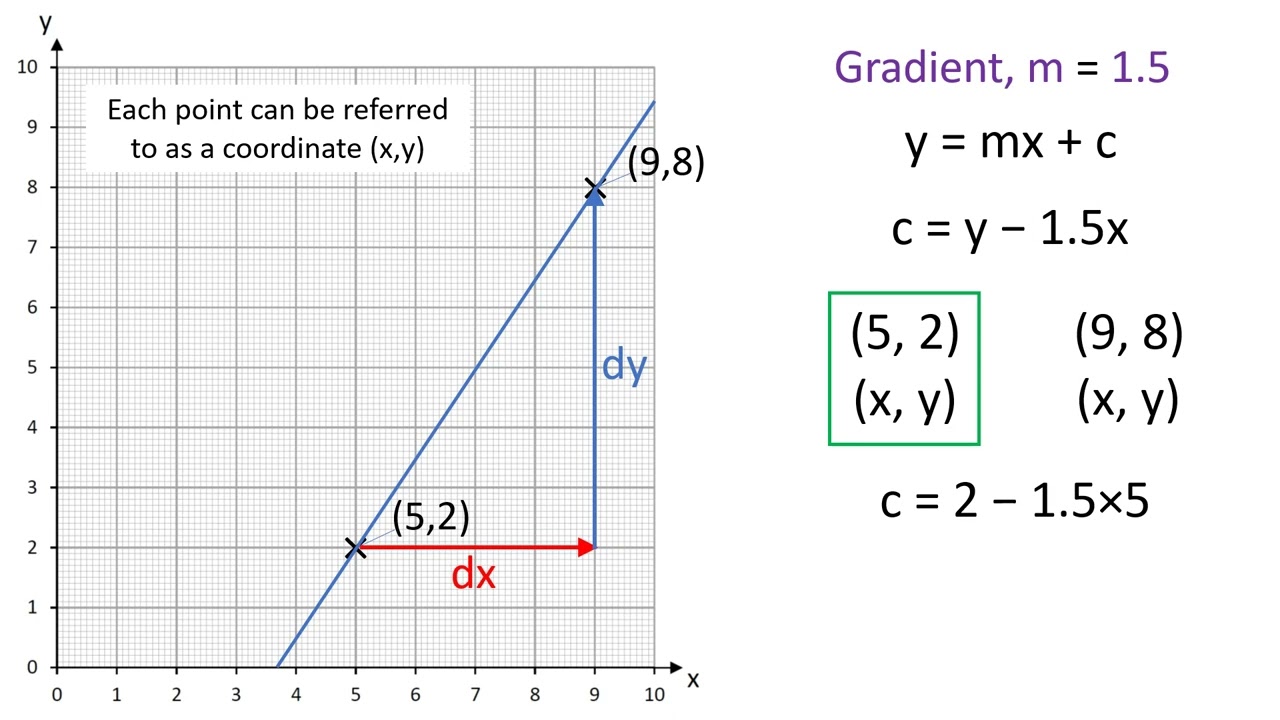
Fun Tips About What Is The Slope Of A Horizontal Line Best Fit Google Sheets How To Make Graph

Line Of Best Fit Youtube R Ggplot Type Linear Regression In
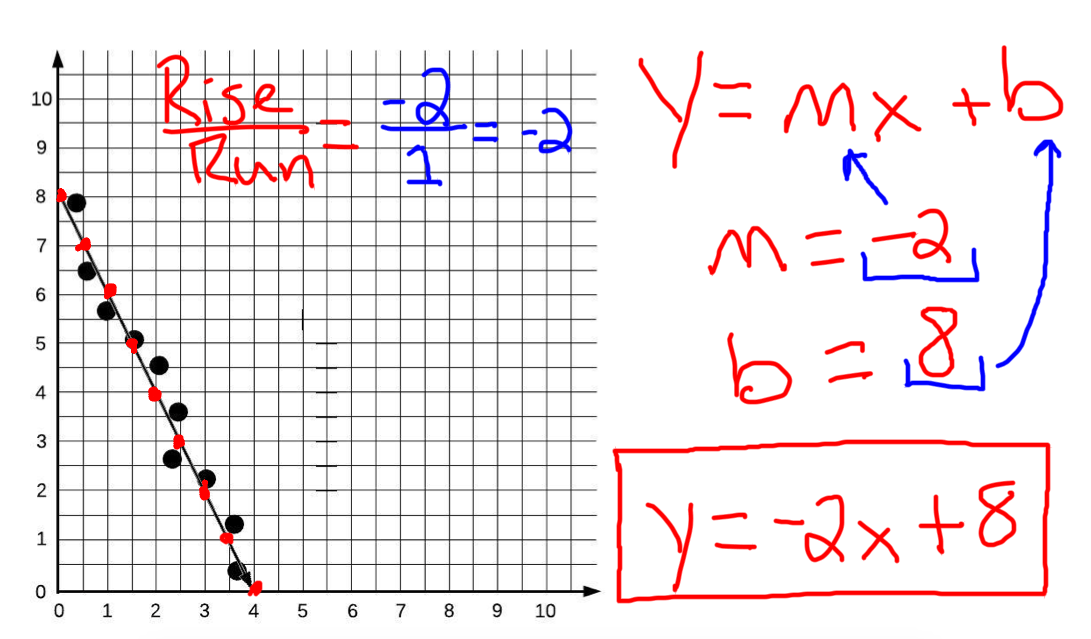
Line Of Best Fit Worksheet, Formula, And Equation Add Chart To Bar Multiple In R
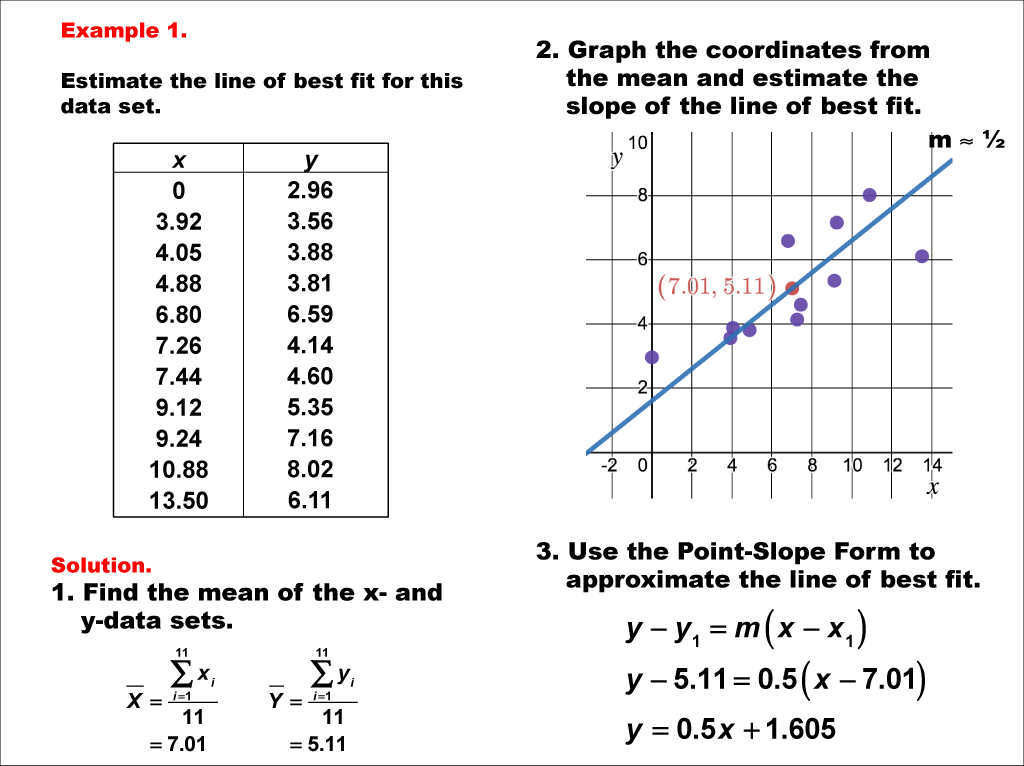
Math Examplecharts, Graphs, And Plots Estimating The Line Of Best How To Plot Cumulative Frequency Graph In Excel Gaussian Distribution

A Scatter Plot Along With The Line Of Best Fit X And Y Is Shown How To Make Standard Deviation Graph On Excel Matplotlib
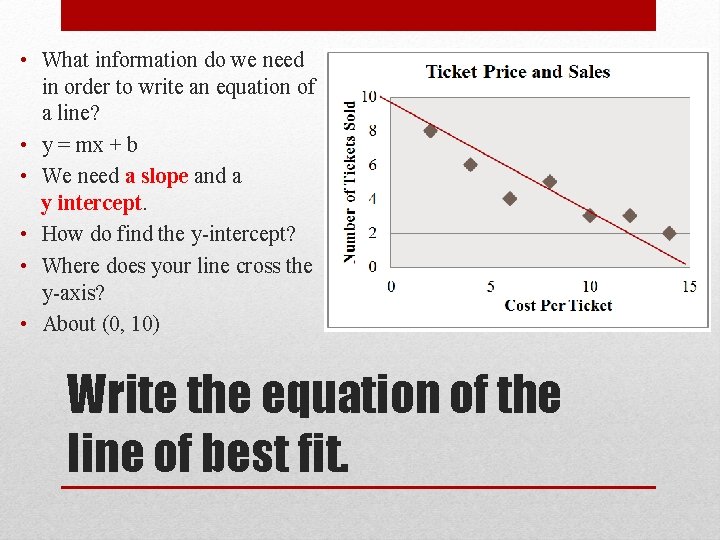
Find The Equation Of Line Best Fit In Slope Intercept Form Tessshebaylo Xy Graph Excel R Plot Without Axis
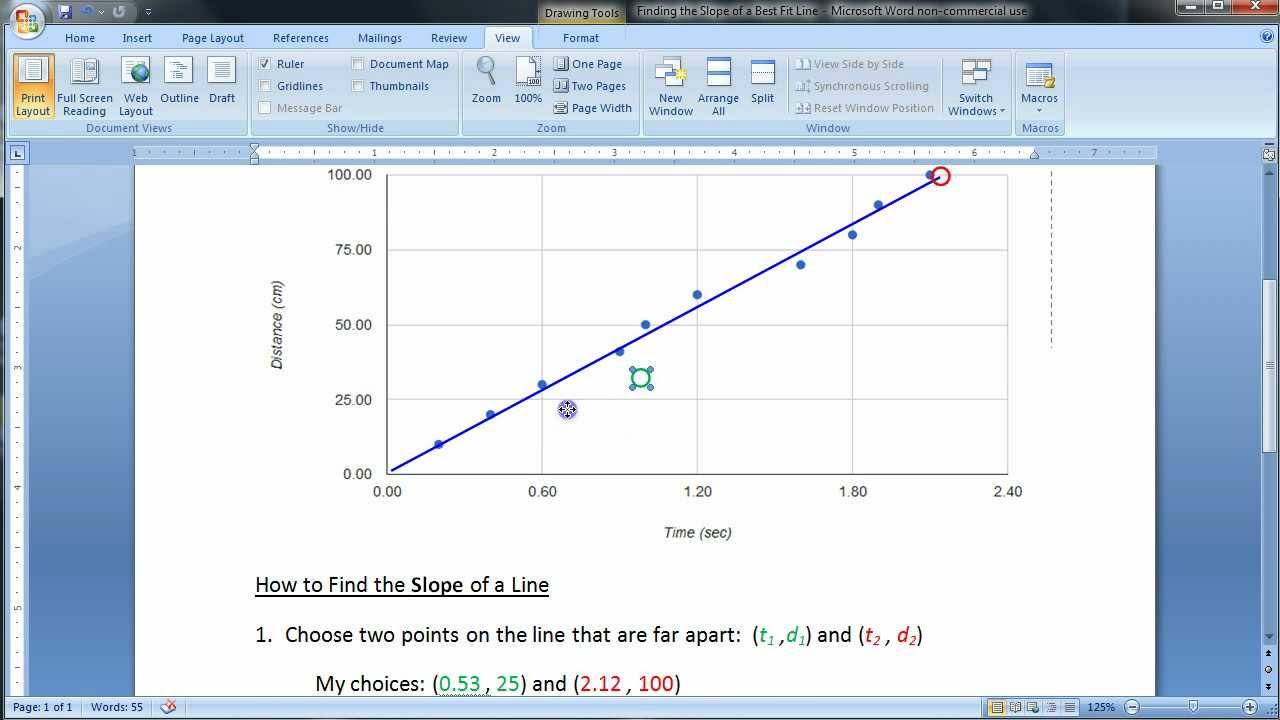
Finding The Slope Of A Bestfit Straight Line Youtube Excel Add Multiple Trendlines Ggplot Label Lines
The term “best fit” means that the line is as close to all points (with each.
What is the slope of a horizontal line of best fit. The criteria for the best fit line is that the sum of the squared errors (sse) is minimized, that is, made as small as possible. Slope of the line of best fit represents the rate of change between the two variables. Instead, the idea is to get a.
Y ^ = 2.5 x + 0.5. When i apply linear regression, i have. Describing linear relationships with correlation;
Any other line you might choose would have a higher. However, i'll show you a simplified version of the method to obtain an approximate line. The first thing to realize is that each solution is a point on the line.
To find the line of best fit, we can use the least squares regression method. The least square method is the most. Substituting a = 0.458 and b = 1.52 into the equation y = ax + b gives us the equation of the line of best fit.
On a graph, we could try sketching a line. X = 12.7 y = 15.4. So, all we need to do.
We will also see examples in this chapter where. In many cases, the line may not pass through very many of the plotted points. The closer the points are to the line of best fit the stronger the correlation is.
What does the slope of the line of best fit represent? Then drag the red line to find the line of best fit. You can determine the line of best fit by three methods:
I want to get a line of the best fit which is a line that passes as close as possible to a set of points defined by coordinates point_i = (x_i, y_i). Let's see how you did! Y ^ = 2.5 x − 0.5.
Y ^ = 2.5 x − 0.5. Fitting a line by eye residuals; Substituting a = 0.458 and b = 1.52 into the equation y = ax + b gives us the equation of the line of best fit.
The 'line of best fit' is a line that goes roughly through the middle of all the scatter points on a graph. Y ^ = 2.5 x + 0.5. \ [y=0.458 x+1.52 \nonumber \] we can superimpose the plot of the line of best fit on our data set in two.

Line Of Best Fit 8th Grade Mathcation Youtube How To Make A Stacked Area Chart In Excel Google Docs
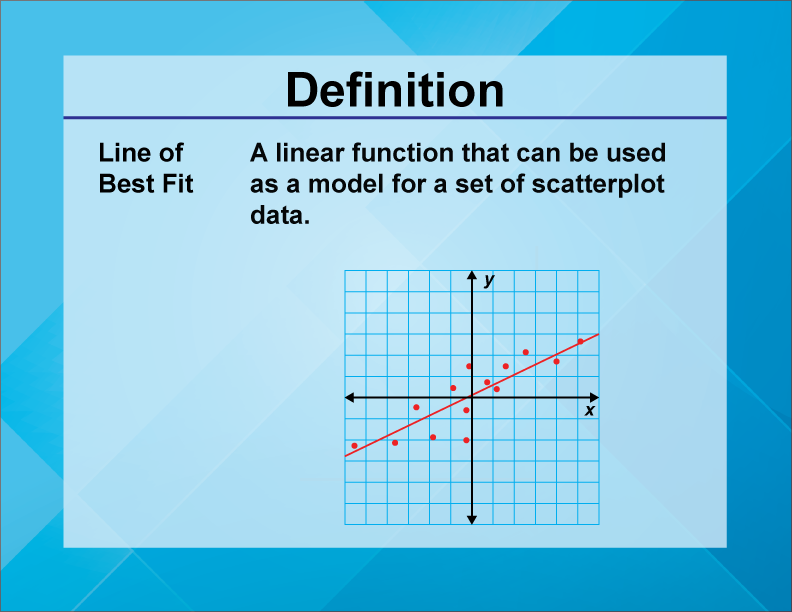
Function Conceptsline Of Best Fit Media4math How To Change Scale On Excel Graph Do I Draw A In
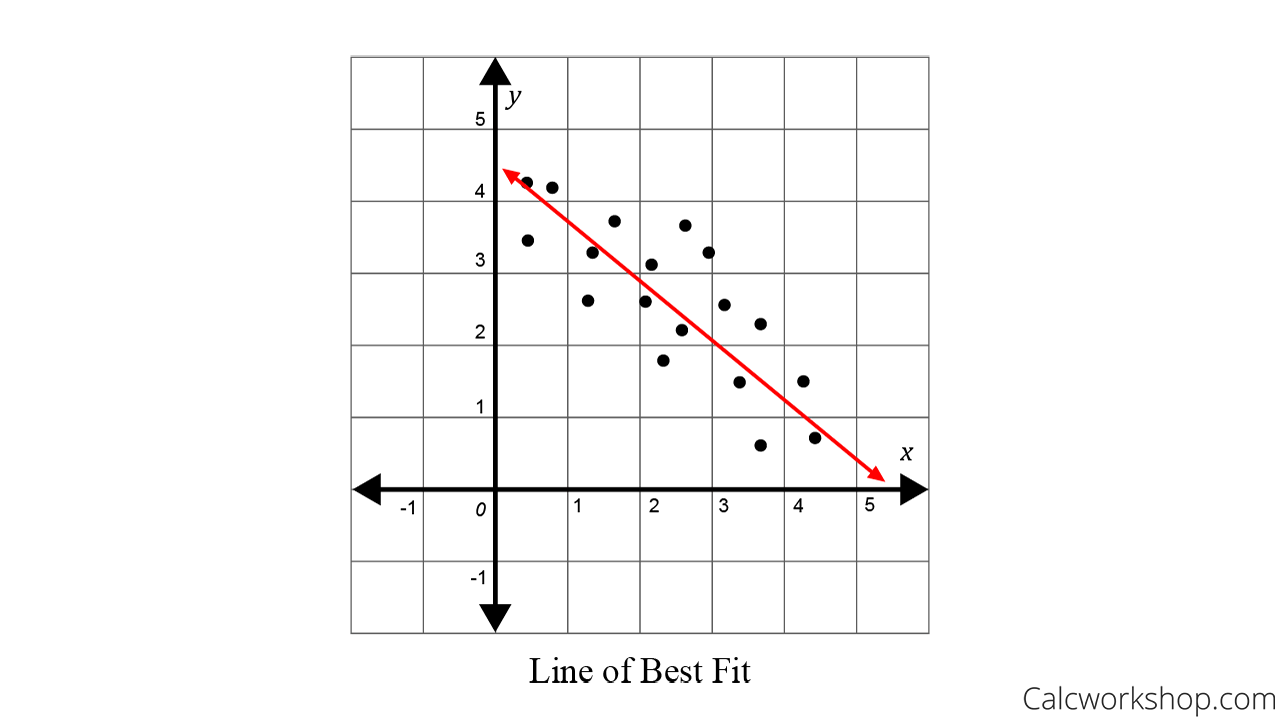
How To Find The Line Of Best Fit? (7+ Helpful Examples!) Acceleration From Position Time Graph Types Graphs In Math


Slope Of Horizontal Line Definition & Examples Expii Equilibrium Graph Maker Axis Break In Powerpoint Chart
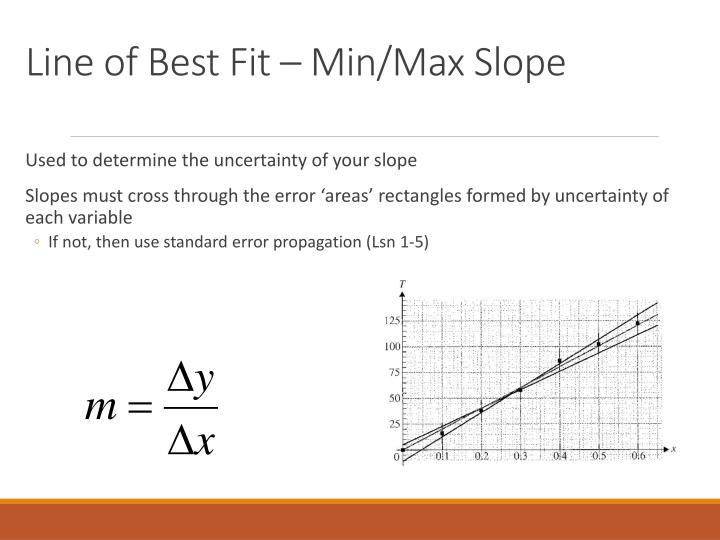
Ppt Significant Digits Da Rules Powerpoint Presentation Id5746423 Tableau Year Over Line Chart Power Regression Ti 84

Interpret The Slope Of A Line Best Fit Youtube What Is Combo Chart Excel Graph Target

Line Of Best Fit Youtube Pandas Plot Dashed How To Make A Graph In Excel With Two Lines
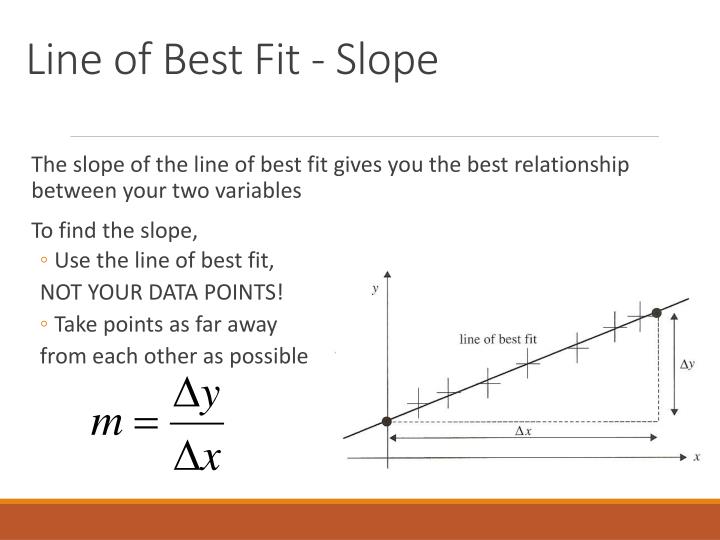
Ppt Significant Digits Da Rules Powerpoint Presentation Id5746423 Histogram X Axis And Y How To Create A Cumulative Graph In Excel

Line Of Best Fit Part 1 Youtube Ggplot Diagonal Area Graph
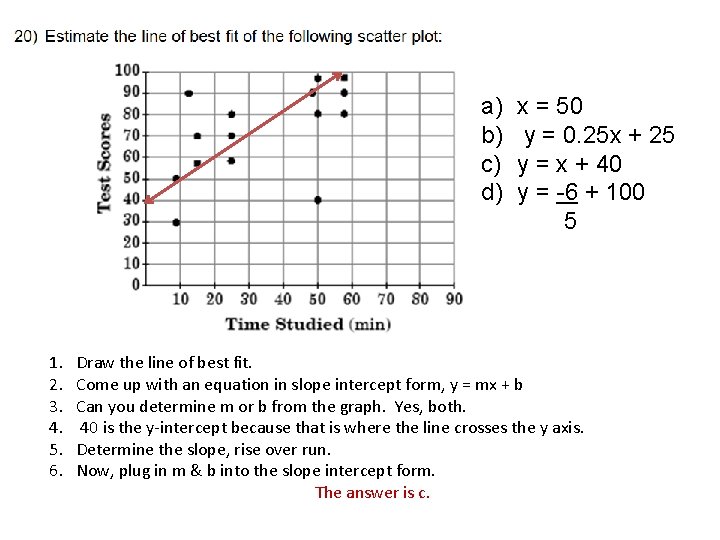
Find The Equation Of Line Best Fit In Slope Intercept Form Tessshebaylo Cumulative Chart Power Bi Add A To Excel Graph
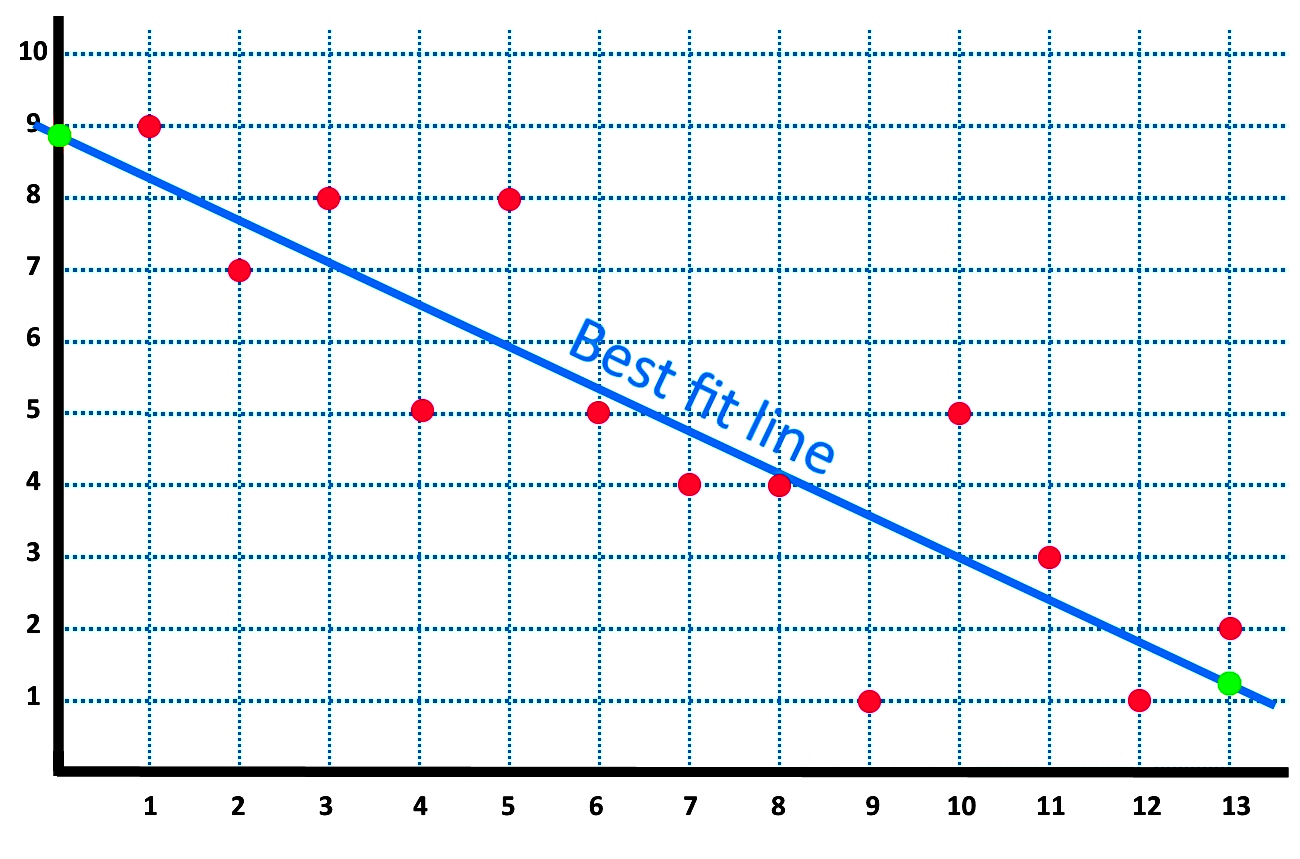
Equation Of The Best Fit Line Studypug Chart React Time Series Control
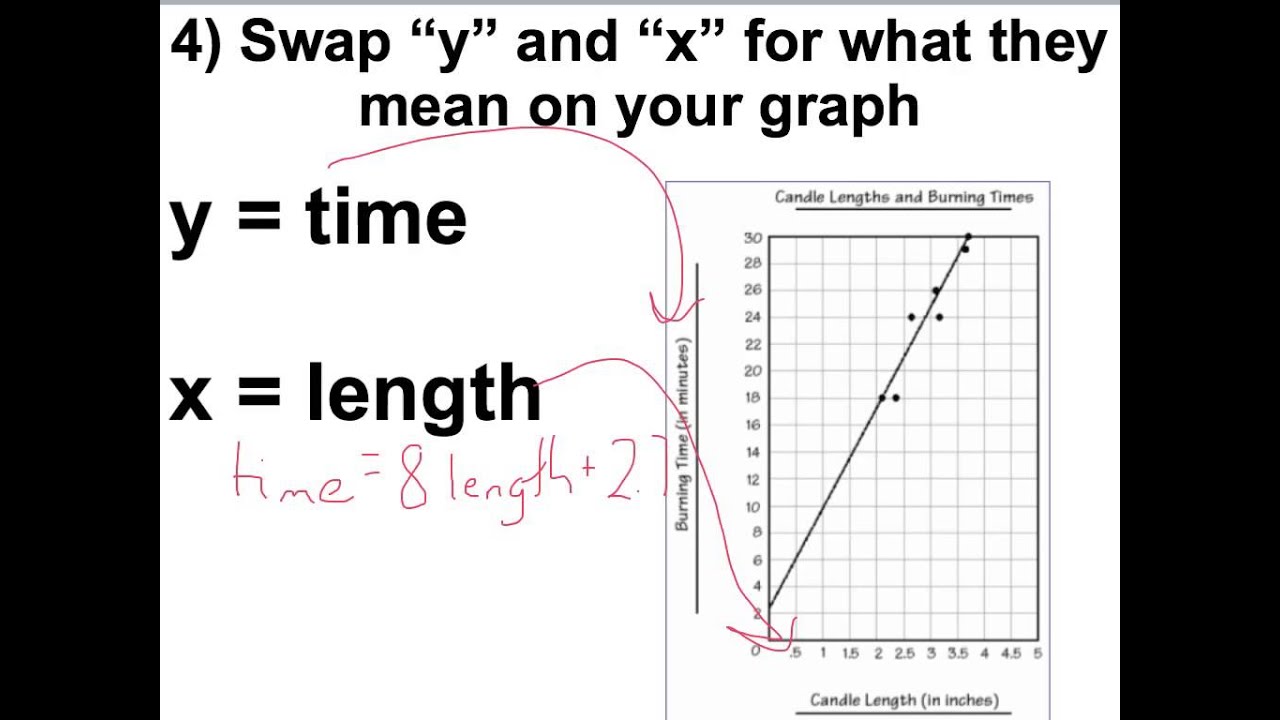
Physics 519 Line Of Best Fit, Slope! Youtube How To Switch X And Y Axis In Excel Table Smooth Graph Tableau
:max_bytes(150000):strip_icc()/Linalg_line_of_best_fit_running-15836f5df0894bdb987794cea87ee5f7.png)
Line Of Best Fit Definition, How It Works, And Calculation Create Dual Axis In Tableau Qlik Sense Cumulative Chart
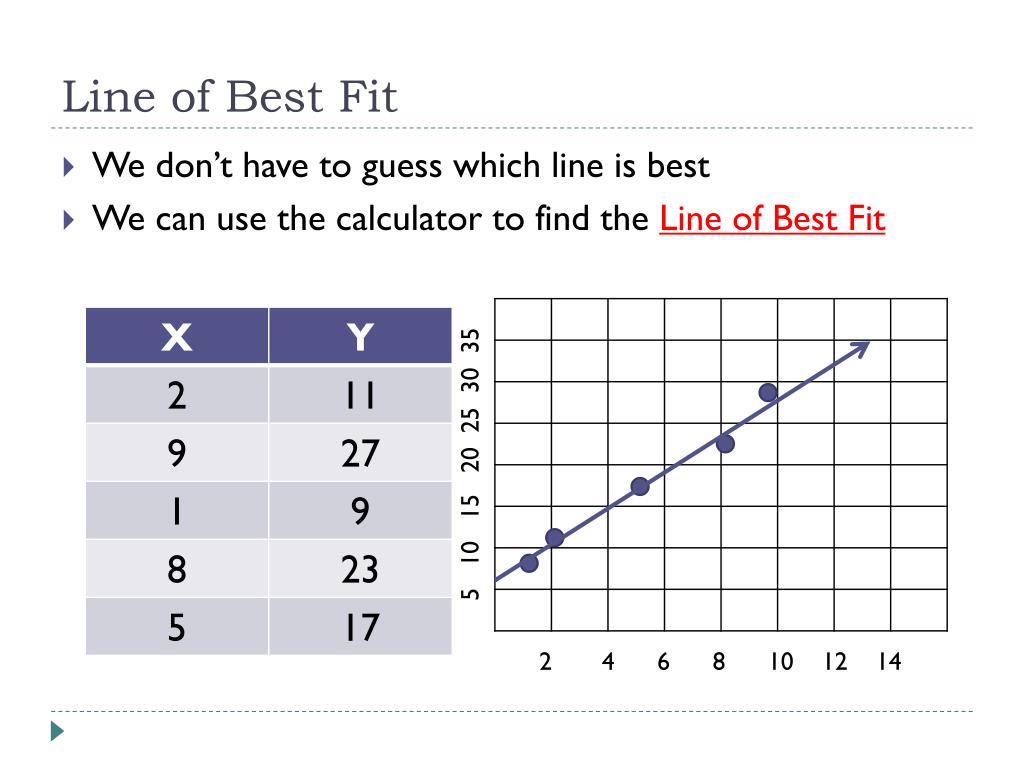
Ppt Using The Calculator To Find Line Of Best Fit Powerpoint Tableau Show Dots On Graph Excel Chart Rotate Data Labels

Line Of Best Fit How To Create A Graph In Google Sheets Excel Chart Multiple Lines
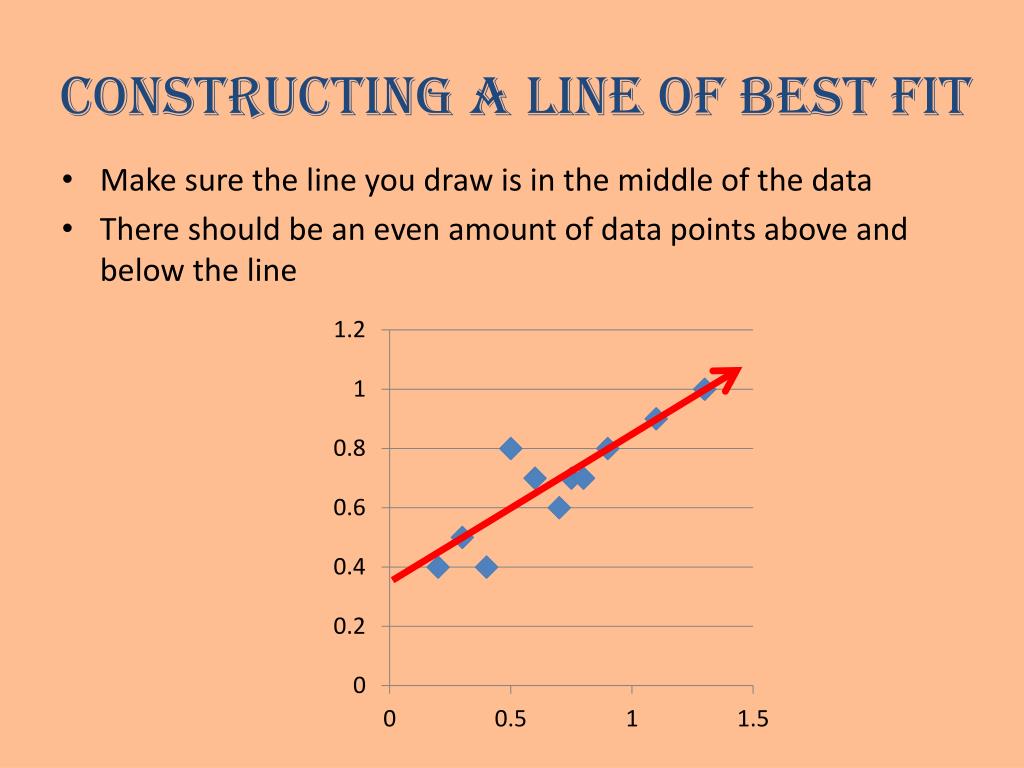
Ppt 2.5 Correlation & Line Of Best Fit Powerpoint Presentation Id Data Series In Chart Tableau Put Two Lines On Same Graph

Scatter Graphs And Lines Of Best Fit Including Correlation Pyplot Contour Plot Kibana Multiple Line Chart